
We won't understand the Spartan project if we don't realize what it is based on and what it was created for. We can extremely simplify it by saying that it is based on Internet Explorer and was created because of the rapidly developing Chrome. But this view from the express train deprives us of the most important knowledge. If I call IE 1-6 the first era and IE 7-11 the second era, now the third era begins. I can't help but compare it to a rocket, because Spartan is the process of separating the second rocket stage from the third.
Mosaic
In 1992, the University of Illinois wrote the Mosaic web browser. It was neither the first nor the last browser. But it was the first browser to display images together with text. Spyglass, the business arm of NCSA, borrowed the source code of this browser for a reference implementation and created its own Spyglass Mosaic Viewer. From today’s point of view, it was important that it ran on Windows. Its source code was licensed by Netscape and the browser was named Netscape Navigator. The browser was a great success and became the de facto standard.
Microsoft wanted to do this business as well, so it also licensed the Spyglass Mosaic source code and named the browser Internet Explorer. He was supposed to pay Spyglass a share of the profits from the sale of the browser. But Microsoft has started giving it away for free. Understandably, Spyglass didn't like this, because the share of nothing is quite small and it sued Microsoft for $8 million.
Browser War
Internet Explorer was a kind of bonus to Windows 95, just like BitLocker to Windows Vista. At that time, the foundations of the web were being laid, CSS and HTML were being created. The standards were still being formed, so it happened that Netscape implemented CSS differently than the W3C people imagined. The website was written to display correctly, not to be strictly according to the standard and displayed strangely. The Internet Explorer team had to decide whether to strictly follow the standards or maintain compatibility with Navigator. They decided not to break the website and implement CSS so that the pages would be displayed the same everywhere. But the W3 consortium stubbornly insisted on its concept and gave browser manufacturers a list of points in which their implementations differ from the standard. Therefore, Internet Explorer had two rendering modes in version 6. One according to standards and one for compatibility with Navigator. The scissors began to open slowly and inconspicuously.
XML Revolution
Everything seemed to be in order. It was assumed that the new pages would be written for the standard mode and the compatible mode (now referred to as Quirks) would be for the life of the already created pages. But at that time, the XML revolution was in full swing. XML has finally provided a sufficiently expressive form of how to structure, or more precisely, how to express the semantics of data. Although the syntax of HTML and XML is based on SGML, somehow the prevailing opinion was that XML is more elegant than HTML. It seemed to be obsolete and was to be replaced by XHTML. A proper XML document starts with an XML prologue (which is not mandatory if the page is UTF-8 encoded). And that was the problem. Internet Explorer did not support XHTML, and the occurrence of prolog switched the rendering mode from standard to compatible mode. Instead of giving up on XHTML, web designers competed to see who would pass the code validator unscathed. Problems of pages written according to standards caused by rendering in compatible mode were solved by special fixes designed only for IE. Many websites were created that were written according to standards, but in IE they were rendered according to different rules. This period lasted an unusually long time. IE 7 was released 5 long years after the introduction of IE 6. All of this opened the scissors completely.
HTML5
Do you know why HTML5 has the doctype it has? It is the only doctype that does not switch to compatibility mode by any of the browsers. The goal of HTML5 was not so much to bring new things as to capture the current state. Standards finally began to be written with regard to what the reality was. It should be noted that it was not W3 who came up with this, but the WHATWG. At the same time, however, the effort to version HTML was gone.
So far, all browsers have made do with three rendering modes – standards, almost standards and quirks. Except for Internet Explorer. It had to maintain backward compatibility with modifications intended only for it, which often abused deviations from standards. Thanks to this, the term CSS hack has become common for this procedure . And so, in addition to switching between rendering modes, switching between browser versions began, because rendering modes naturally evolved between versions.
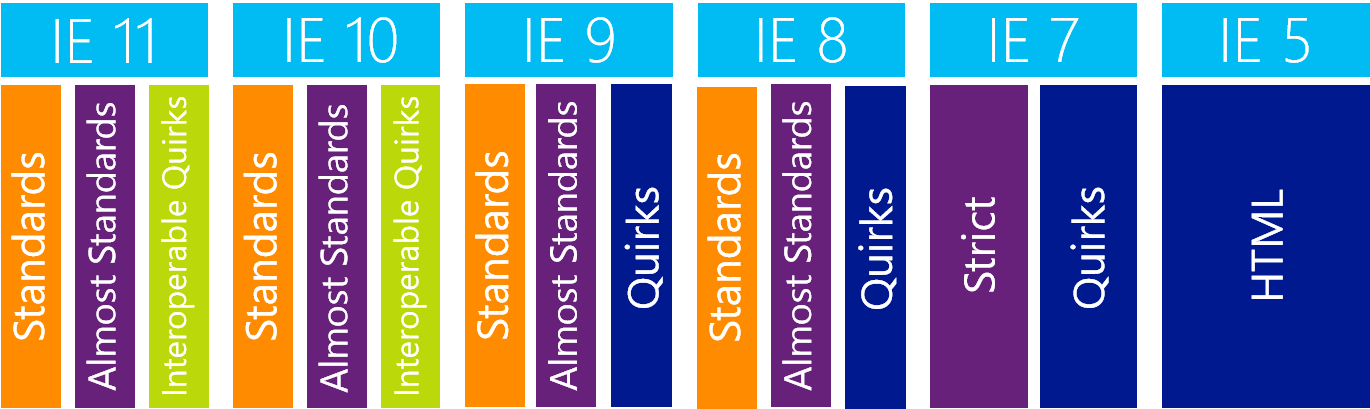
Microsoft had the idea that developers would declare which version of which browser the website was intended for. This captures the status of the implementation of standards in specific browsers at a specific time. Then it will be immediately clear how the browser should behave. At first, it worked, but over time one big problem became apparent.
Edge
Not all browsers complete the implementation of all standards at the same time. This in itself would not matter if the web developer did not fix his website on a specific version of IE according to Microsoft’s recommendation. For example, if there is SVG on the website and the website is fixed on IE 8, which did not yet know SVG, there may be how many higher versions of IE with SVG support are wanted, but SVG simply will not appear in them because the IE 8 compatible mode is used. And we already know from experience that relying on everyone to update their websites regularly is very naïve. There was nothing left but to start ignoring the fixation on a specific browser version. But with that, the whole IE backward compatibility system suddenly lost its meaning.
Backward and forward compatibility
The history of Internet Explorer teaches us how important backward and forward compatibility is, and that trying to find an academically appealing solution regardless of the obvious reality is futile.
Backward compatibility means rendering all current HTML documents in the new version of the browser as they were rendered in the previous version. The Internet Explorer 7 prototype has fixed many bugs in the previous version. But when its developers showed it to the people from Yahoo, they learned from them that no one would use it because it was not compatible with anything.
With the ability to target an HTML document to a specific version, IE lost its forward compatibility. When something new was added to the document, but what the browser had learned in the meantime, everything was still the same.
Efforts to improve something in a way that throws away everything that is so far and starts again from the beginning have always failed. It is desirable to behave this way when it comes to scientific hypotheses, but undesirable when it comes to money.